LIBRERÍAS DE PHYTON
- ANTONY BRAYAN LLACCHUA IMAN
- 25 nov 2023
- 5 min de lectura

Actualizado: 2 dic 2023
Es aquella herramienta que contiene módulos incorporados (escritos en C) que brindan acceso a las funcionalidades del sistema como entrada y salida de archivos que serían de otra forma inaccesibles para los programadores en Python, así como módulos escritos en Python que proveen soluciones estandarizadas para los diversos problemas que pueden ocurrir en el día a día en la programación. Las librerías de Python son una parte esencial del ecosistema del lenguaje, ya que permiten a los desarrolladores acceder a un conjunto amplio de funcionalidades específicas, como manipulación de cadenas, operaciones matemáticas, acceso a bases de datos, manipulación de archivos, creación de interfaces gráficas, procesamiento de datos científicos, creación de sitios web, entre muchas otras.
Además permiten realizar distintas funciones, ahorrando tiempo y esfuerzo al programador. Gracias a la amplia variedad de librerías existentes, Python es uno de los lenguajes más flexibles y potentes que pueden utilizarse.

SEABORN
Seaborn es una biblioteca para crear gráficos estadísticos en Python. Proporciona una interfaz de alto nivel para matplotlib y se integra estrechamente con las estructuras de datos de pandas. Las funciones de la biblioteca seaborn exponen una API declarativa orientada a conjuntos de datos que facilita la traducción de preguntas sobre datos en gráficos que pueden responderlas. Cuando se le proporciona un conjunto de datos y una especificación del gráfico a realizar, seaborn asigna automáticamente los valores de los datos a atributos visuales como color, tamaño o estilo, calcula internamente transformaciones estadísticas y decora el gráfico con etiquetas de eje informativas y una leyenda. seaborn está diseñado para ser útil durante todo el ciclo de vida de un proyecto científico. Al producir gráficos completos a partir de una única llamada a función con argumentos mínimos, seaborn facilita la creación rápida de prototipos y el análisis exploratorio de datos.

Esta librería se importa habitualmente con el alias sns.

Junto a seaborn se importan también las librerías matplotlib (pues, en ocasiones, hay que recurrir a ella para acceder a funcionalidad no ofrecida por seaborn), pandas y NumPy (en algunos ejemplos crearemos estructuras de datos basadas en estas librerías) y la librería warnings para ocultar ciertos mensajes de aviso que genera seaborn (al respecto de futuros cambios de funcionalidad).

VENTAJAS DE SEABORN
La biblioteca Seaborn ofrece varias ventajas importantes. Ofrece distintos tipos de visualizaciones. Tiene una sintaxis reducida y temas predeterminados muy atractivos.
Es una herramienta ideal para la visualización estadística. Se utiliza para resumir datos en visualizaciones y distribución de datos.
Además, Seaborn está mejor integrado que Matplotlib para trabajar con data frames de Pandas. Por último, es una extensión de Matplotlib para crear bonitos gráficos con ayuda de Python a través de un conjunto de métodos más sencillos.
Manejo de los datos: Seaborn es capaz de “entender” directamente un DataFrame, representando fácilmente distribuciones de datos o agregaciones, sin desarrollar muchas líneas de código.
Visualizaciones disponibles: Los gráficos ayudan a entender los datos y para ello, es necesario seleccionar el gráfico más adecuado. La galería de seaborn es una de las más amplias, desarrollada para representar análisis estadísticos de forma sencilla.
Personalización: El aspecto visual de un gráfico que tan laborioso es con matplotlib, se desarrolla de forma muy sencilla con seaborn.
ANALISIS DE DATOS CON SEABORN
Seaborn dispone de diferentes gráficos para la representación de la relación que guardan los datos de un DataFrame.
Barplot: La función barplot permite crear gráficos de barras en seaborn. Esta función calcula la media para cada variable categórica y la representa con barras, así como sus intervalos de confianza con barras de error. Muy recomendable para la visuación de datos agregados, como la media. Ejemplo:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="white", context="talk")
rs = np.random.RandomState(8)
# Set up the matplotlib figure
f, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(7, 5), sharex=True)
# Generate some sequential data
x = np.array(list("ABCDEFGHIJ"))
y1 = np.arange(1, 11)
sns.barplot(x=x, y=y1, hue=x, palette="rocket", ax=ax1)
ax1.axhline(0, color="k", clip_on=False)
ax1.set_ylabel("Sequential")
# Center the data to make it diverging
y2 = y1 - 5.5
sns.barplot(x=x, y=y2, hue=x, palette="vlag", ax=ax2)
ax2.axhline(0, color="k", clip_on=False)
ax2.set_ylabel("Diverging")
# Randomly reorder the data to make it qualitative
y3 = rs.choice(y1, len(y1), replace=False)
sns.barplot(x=x, y=y3, hue=x, palette="deep", ax=ax3)
ax3.axhline(0, color="k", clip_on=False)
ax3.set_ylabel("Qualitative")
# Finalize the plot
sns.despine(bottom=True)
plt.setp(f.axes, yticks=[])
plt.tight_layout(h_pad=2)Salida:

2. Histograma con hisplot: Para conocer la distribución de los datos, el histograma es una herramienta básica, sin embargo, esta representación está muy influenciada por el número de bins que se seleccionen y el ancho de cada uno.
Ejemplo:
import numpy as np
import seaborn as sns
# Simulación de datos
rng = np.random.RandomState(0)
x = rng.normal(0, 1, size = 1000)
df = {'x': x}
# Histograma
sns.histplot(x = x)
# Equivalente a:
sns.histplot(x = "x", data = df)Salida:

3. KDE plots(Kernel Density Estimation plots). Genera mejores representaciones de distribuciones de datos que un histograma al suavizar la forma de los datos, pero no aporta información estadística.
Ejemplo:
import numpy as np
import seaborn as sns
# Simulación de datos
rng = np.random.RandomState(4)
x = rng.normal(0, 1, size = 100)
df = {'x': x}
# Gráfico de densidad
sns.kdeplot(x = x)
# Equivalente a:
sns.kdeplot(x = "x", data = df)Salida:

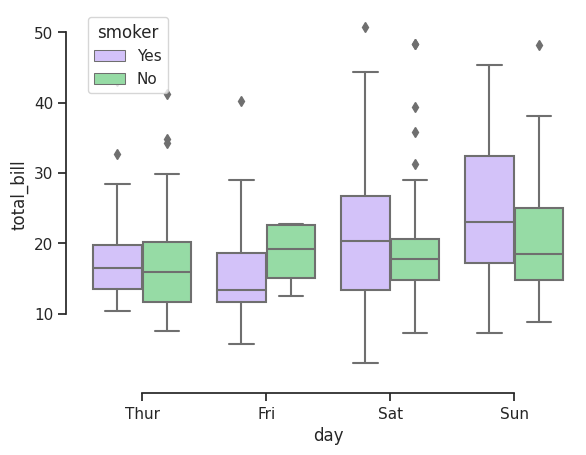
4. Box plots: Útiles para conocer los rangos de datos, si existen outliers, la media y el rango intercuartil en el que se distribuyen los datos.
Ejemplo:
import seaborn as sns
sns.set_theme(style="ticks", palette="pastel")
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Draw a nested boxplot to show bills by day and time
sns.boxplot(x="day", y="total_bill",
hue="smoker", palette=["m", "g"],
data=tips)
sns.despine(offset=10, trim=True)
Salida:
5. Violin plots: La conjunción de KDE + box plots, clave para comparar distribuciones. Un violin representa la distribución, su media, el rango intercuartil y el intervalo de confianza de 95% en el que se distruyen los mapas.
Ejemplo:
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
# Load the example dataset of brain network correlations
df = sns.load_dataset("brain_networks", header=[0, 1, 2], index_col=0)
# Pull out a specific subset of networks
used_networks = [1, 3, 4, 5, 6, 7, 8, 11]
used_columns = (df.columns.get_level_values("network")
.astype(int)
.isin(used_networks))
df = df.loc[:, used_columns]
# Compute the correlation matrix and average over networks
corr_df = df.corr().groupby(level="network").mean()
corr_df.index = corr_df.index.astype(int)
corr_df = corr_df.sort_index().T
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11, 6))
# Draw a violinplot with a narrower bandwidth than the default
sns.violinplot(data=corr_df, bw_adjust=.5, cut=1, linewidth=1, palette="Set3")
# Finalize the figure
ax.set(ylim=(-.7, 1.05))
sns.despine(left=True, bottom=True)Salida:

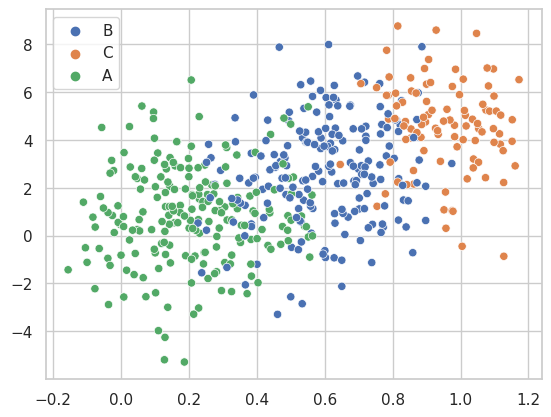
6. Scatterplot: Ideal para la representación de correlaciones y cómo una variable afecta a la otra.. Usando la función scatterplot de seaborn es muy sencillo crear un gráfico de dispersión por grupo. Tendrás que pasar tu variable categórica al argumento hue de la función.
import numpy as np
import pandas as pd
from random import choices
# Semilla
rng = np.random.RandomState(0)
# Simulación de datos
x = rng.uniform(0, 1, 500)
y = 5 * x + rng.normal(0, 2, size = 500)
grupo = np.where(x < 0.4, "A", np.where(x > 0.8, "C", "B"))
grupo2 = choices(["G1", "G2"], k = 500)
x = x + rng.uniform(-0.2, 0.2, 500)
# Conjunto de datos
df = {'x': x, 'y': y, 'grupo': grupo, 'grupo2': grupo2}
import seaborn as sns
sns.scatterplot(x = x, y = y, hue = grupo)Salida:
7. Heatmatp: Permite crear mapas de calor o gráficos de correlación en Python con seaborn. Puedes pasar un conjunto de datos 2D o un data frame de pandas. En caso de utilizar un data frame de pandas los nombres de las filas y las columnas serán usados como etiquetas para los ejes.
Ejemplo:
import numpy as np
import seaborn as sns
# Simulación de datos
np.random.seed(1)
data = np.random.rand(10, 10)
sns.heatmap(data)Salida:

En conlusión, la librería seaborn con estos sencillos gráficos es muy fácil visualizar la relación entre variables y representar estadísticamente el DataFrame sin necesidad de muchas líneas de código, para profundizar en el análisis de datos que necesitas de forma sencilla.


Comentarios